

Building multi-agent tools for engineering

AI is having a profound impact on engineering, pushing the limits of what we can achieve as individuals and as teams. At NewStore we see it as our duty to figure out how AI will influence our established engineering practices, pushing us to do our best work yet now that the tools of the trade are so rapidly evolving. This post is part of a series where we share our experiments and experiences.
The idea of multi-agent systems is much older than the recent wave of LLM-based agents. Traditionally, a multi-agent system would consist of multiple autonomous agents that work on solving distinct parts of a complex problem. Agents wouldn’t necessarily need to be “smart”, they could be rule-based or act as a model of part of the problem space. LLMs have given a new meaning to what agents can do. In this new definition, each agent is a LLM with a distinct set of tools and instructions. The tools and instructions make it good at a specific part of a more complex problem. Each agent in a multi-agent system can have a different LLM, e.g. picking a model that is better at a specific task or one that is cheaper but still good enough.
LLM-based multi-agent systems are often built using agent orchestration frameworks, such as LangChain or Google Agent Development Kit. These frameworks have out-of-the-box support for managing conversation state, detailed tracing and other advanced use cases, but in essence boil down to the following. They allow you to define agents and provide a way for agents to call other agents with a specific prompt and receive that agents output as a response.
In this post we’ll discuss two multi-agent tools:
A Slack-bot that helps us triage reported issues with our shopping apps
A research agent that helps us respond to incidents
Testing apps from within Slack
Issues reported by our customers demand attention, but can also distract from regular product development. We set out to build a tool that attempts to reproduce the issue automatically, helping us to spend time on the issues with the most impact.
Our first multi-agent tool builds upon the testing agent we introduced in a previous post. That agent is able to test release builds of our shopping apps close to how a human would, by interacting with the app on a virtual device according to test cases written in English. The tests run as part of our GitLab CI set-up on our own M4 Mac Mini runner. To unlock the agent for use in a multi-agent system, we updated the CI job to check for the presence of a “custom instructions” environment variable. When present, the agent uses those instructions instead of the default test cases. This seemingly small addition makes a huge difference: other agents can now invoke it by triggering the pipeline with custom instructions.
We thought it would be really useful if we could trigger these custom test runs from within Slack. For example, this would let us quickly reproduce issues while discussing them, or in response to a new app store review (we receive those in a dedicated Slack channel). To achieve this we introduced a second agent as the conversational front-end of the tool. We’ve named it Shoppy.
Shoppy can be pulled into a conversation on Slack by mentioning it. It functions as a conversational agent in the way we’ve come to expect from ChatGPT and others. On top of that we’ve given it the tools it needs to trigger a test run. To trigger a test run, we need to specify the app to test, its version (or git ref), its platform and the test instructions. The agent is instructed to attempt to deduce these from the conversation. It is helped by a couple of tools. One provides access to our list of brand GitLab projects, so it can know which app the conversation is about. We also gave it access to the git tags inside those projects that correspond to released versions of the app. It has another tool that fetches the current live version from the App Store or Play Store. Once all the information has been gathered and confirmed by the user, it calls a final tool that makes a call into the GitLab REST API to trigger the pipeline that’ll run the test.
Shoppy’s back-end is registered as a webhook for GitLab pipeline events. When it receives a callback, the information from the callback is given to Shoppy (as “system messages”) together with the corresponding Slack thread’s history. Shoppy can then formulate a response that fits within the context of the conversation. It can also decide to take no action for intermediate updates, which is its default instruction. But if a user requested to be kept in the loop (“Trigger the run and relay all pipeline progress”) Shoppy will do that.
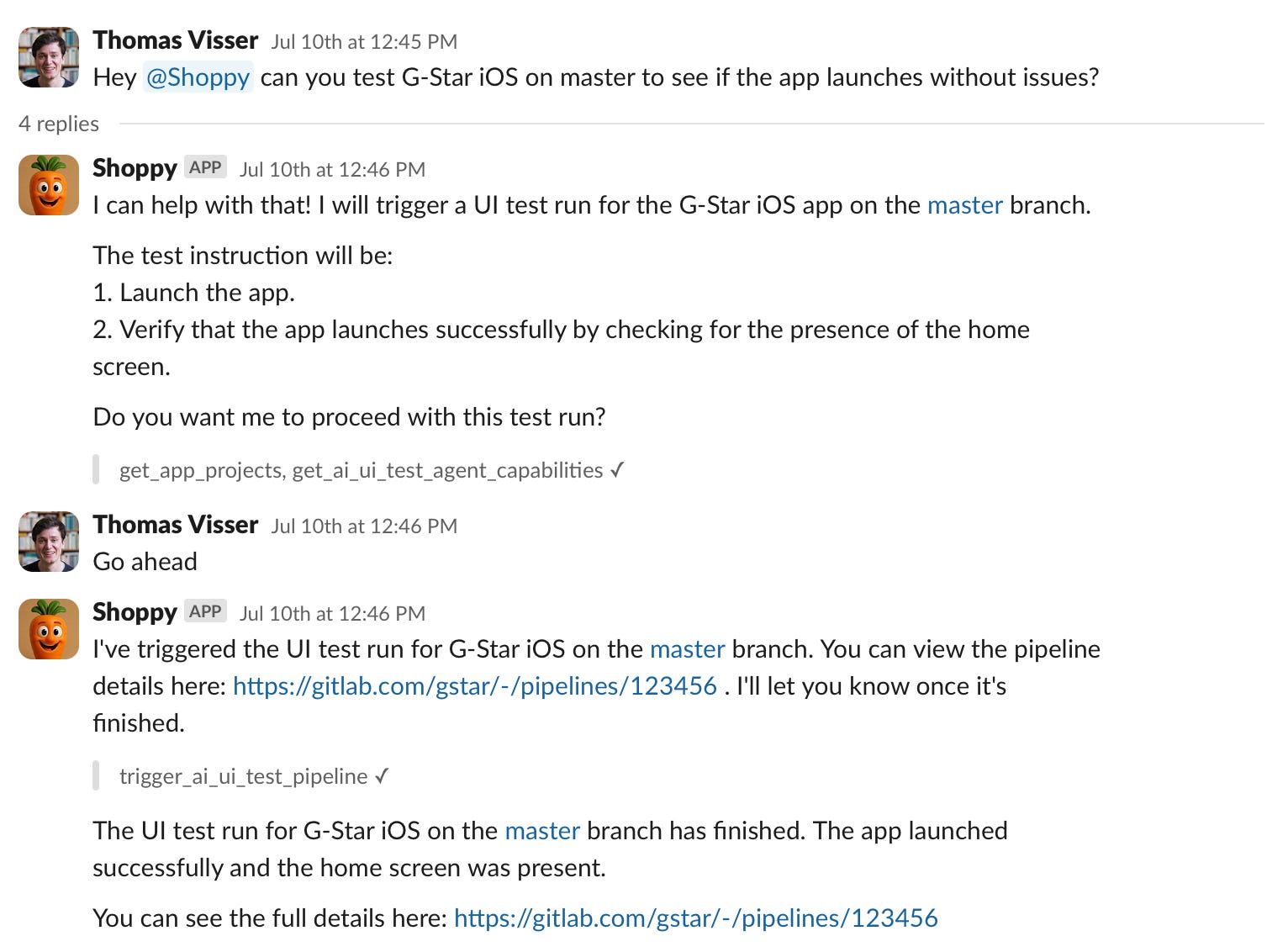
When the run has completed, Shoppy will post an update to the thread with a link to the pipeline. The engineers can inspect the test run’s artefacts, including a screen recording of the device, network traffic and various logs. This is excellent input to further triage the issue and decide whether or not to pick it up with urgency. Engineers can stay focused on their tasks while Shoppy collects actionable information in the background.
Shoppy is a Python application deployed on Google Cloud Run. It uses Bolt to integrate with Slack and googleapis/python-genai (using gemini-2.5-flash on the Gemini API) for the LLM. All incoming events (Slack messages, GitLab pipeline messages and more) enqueue a task on a Cloud Task queue, ensuring isolation from the calling services and synchronized processing of messages within a conversation. Conversation state is stored in both Slack (user + agent messages) and an internal database (tool calls).
Incident “deep” research
NewStore organizes internal hackathons twice a year. Teams get a week off from their normal duties (mostly) to build cool stuff and win fun prizes. Hackathon projects frequently end up getting shipped not long after, shaping the future of our platform and our way of working.
For our project, we assembled a small team to work on extending Shoppy’s capabilities so it can help us in the times we need it the most: when you’re on-call and a severe issue happens. Even though we didn’t win, we’re excited to share what we’ve built. The results were truly impressive and now we can’t wait for our next incident. Joking aside: because actual incidents are infrequent we had to create a sophisticated fake incident for our hackathon project. We built a demo web app that we actually deployed, with observability and alerting through PagerDuty, set up CI/CD and introduced a bug through an innocent looking commit. Any less elaborate fake incidents did not fool the agent into doing its best. Curious? Take a look at the relevant code to see if you can spot the issue. Spoiler: “Deep Shoppy” figured it out (no pressure).
To build an agent that would be useful during incident response, we hypothesized it would need two things: access to many information sources and a set-up that would have it thoroughly investigate these sources until it found something useful. For information access, we could implement tools. For the “investigative loop”, we looked into something that would behave like OpenAI’s Deep Research, spending minutes on autonomous fact finding and analysis. We selected LangChain’s Open Deep Research project as the basis of our agent, seeing it could provide that agentic research loop. It defines a multi-agent system with a supervisor agent and many researcher sub-agents. The supervisor agent would divide the research question into distinct sub-questions. For every sub-question, a researcher agent would be spawned, which would call tools until it found an answer. The quality of the answer would depend on the quality of the tools, and that’s where we spent most of our time.
We developed 22 tools, giving access to four information sources: PagerDuty, GitLab, Google Cloud Platform and its own previous reports. The last one is different from the others, because it’s self-referential. It gives the agent access to its previous findings, allowing it to build upon its previous research.
We implemented the PagerDuty tools using python-pagerduty. We built tools that would allow the agent to start a research task with just an incident id. We gave it access to incident details, related alerts, details of the affected service, past incidents of the service, service change events and more.
We implemented the GitLab tools using python-gitlab. We built a first set of tools that would allow the agent to figure out which projects are relevant to an incident, which is not always clearly defined in PagerDuty. The tools enable the agent to search for groups and projects and read a project’s readme. Once it has the relevant projects, a second set of tools allow it to investigate. These tools provide it with access to the project’s CI/CD yaml, pipelines, code search and diffs. We expect the agent to link a specific deployment job to the incident by looking at time and then find the root cause by inspecting the diff between that job and the deployment before that.
Google Cloud Platform has a wealth of relevant data, but for this project we focused on tools for observability, which we implemented using google-cloud-logging. We provided the agent with access to real-time logs and metrics. The logs are useful to find error messages, the metrics help see trends over time. We expect the agent to find which metric belongs to the alert that triggered the incident so it can look at historical data and the metric’s value in the time leading up to the incident.
The Report
With the tools in place, we triggered the fake incident by simulating traffic with k6 and Shoppy went to work.

Here’s what it found:
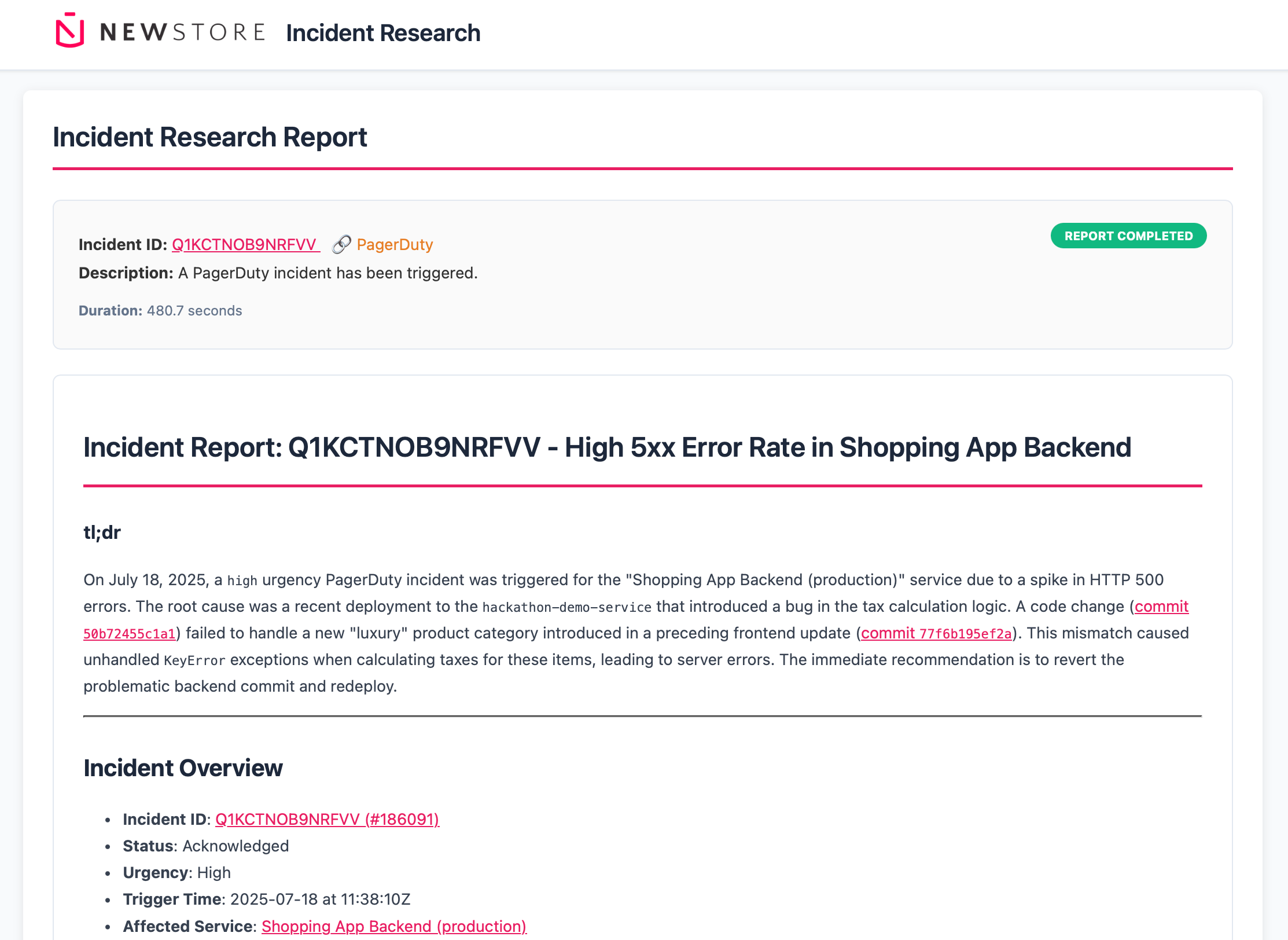
It looked at the incident details in PagerDuty and found the relevant GitLab project and GCP metric
It detected frequent exceptions in the GCP logs (
KeyError: 'luxury')It identified the pipeline that deployed the code causing the issue, suggesting to revert and redeploy
It found the code where the exception was triggered and identified two commits that contributed to the incident
It suggested changes to make to our code to resolve the issue completely
Generating the report took around eight minutes. Here’s a screenshot of the report in a web interface:
Eight minutes is quite long, at least it can feel that way while responding to an incident. There’s no hardcoded maximum time the agent can spend. We can configure how many research sub-agents it is allowed to spawn, but the overall research time also depends on how well the tools are working and varies due to the non-determinism of the model. (Every report is unique.)
To surface potential useful findings sooner, we enabled the agent to relay results from the researcher sub-agents directly to the user. We hooked into the on_chain_end callback and checked for compressed_research output. We forwarded the contents as a system message to Shoppy, which would then pass the information to the user in a Slack thread. While the full report took eight minutes to compile, it forwarded the first findings within 1-3 minutes.
Conclusion
In this post, we’ve shared two of our interconnected experiments with multi-agent engineering tools. We’re excited about their potential, while every interaction gives us new ideas on how to make them better.
Shoppy is showing us the power of integrating in existing processes. We’re already on Slack and Shoppy, by being there, brings more power to our conversations. Using LLMs as a chatbot is nothing new, but having it be part of group chats is new. We’re still learning how to make Shoppy a good conversation partner in this context.
The incident research agent surprised us with its performance. With every tool we gave it, it seemed to get better at its task. There are still a lot of tools to add to give it insight into other major parts of our technology stack. It’ll be interesting to see if the agent’s performance will continue to scale with an even larger number of tools at its disposal.
As with any tooling, it’s a balance between building things yourself or using something existing. After all, we want to be in the business of making the best unified commerce platform. We’re excited to keep exploring how agentic tools can help us achieve that goal.
No generative AI was used in the writing of the post.