

Testing our Shopping Apps with AI

AI is having a profound impact on engineering, pushing the limits of what we can achieve as individuals and as teams. At NewStore we see it as our duty to figure out how AI will influence our established engineering practices, pushing us to do our best work yet now that the tools of the trade are so rapidly evolving. This post is part of a series where we share our experiments and experiences.
In this post, we’d like to share one example of an experiment into how AI changes the way a team at NewStore works. This team is responsible for the development of the platform that powers our Shopping Apps. The experiment is changing the way we test our apps by augmenting traditional testing techniques with AI-powered UI testing.
Our platform is delivering 20+ shopping apps, trusted by brands in 40+ countries and rated five stars by millions of users worldwide. On the app-side, our platform consists of a set of native frameworks for iOS & Android that are shared by all apps using our platform. The frameworks contain the vast majority of all logic. We add brand-specific logic for configuration and theming, which consists of around 1% of an app’s total lines of code. Consequently, the majority of our efforts are focused around the development of the frameworks.
We release the frameworks (internally) on a bi-weekly schedule. We then perform a staggered roll-out of the updated frameworks across the apps. A group of early access brands always receives the latest framework version. The remaining “general availability” apps are updated over the weeks following the initial release.
Testing strategy
The distinction between the shared frameworks on one end and the apps that are built with them on the other can also be seen in the way we’ve structured our testing. We’ve found different approaches that work best for each of them.
The frameworks are tested in a fully automated way, using unit tests (with snapshots) and end-to-end UI tests. For the end-to-end tests, we use a special internal brand app that is separate from any of our customer’s apps and connects to a back-end we have full control over. The tests are written and run using Maestro.
The apps are manually tested by the engineers in our team. When testing the apps, we focus on the integration of the frameworks in the app and any brand-specific logic an app might have. Since the frameworks themselves have been tested separately, we can at this point assume they are stable. But seeing an app update run correctly before we publish it to the app stores is proof that we like to have before every release.
We have to be smart about what we test in the apps. Anything we want to test we’ll have to test 40+ times, which are the apps for 20+ brands on both iOS and Android. Anything times 40 quickly adds up. That’s why we’re investing in two initiatives that we expect to bring down the need for testing the apps. The first is our continuous investment in automated tests for the frameworks. Previous attempts to apply this same approach to testing of our apps failed. The apps are not fully under our control and change frequently. We’ve seen traditional static UI test cases fail because of a temporary sale or a product going out of stock. Testing the apps in an environment that is fully under our control would make the tests less representative. That is why we recently started a second initiative where we are building an AI agent that can test our apps. Our hypothesis was that an AI agent would be able to validate the app’s behaviors, while adapting to changes. Our test cases would then represent the tasks users perform in our apps, which the AI would validate regardless of UI changes across time or across brands.
The AI UI testing agent is already replacing 20% of our test work and we’re looking to increase that to 45% over the course of the next releases. The remainder of this post is a technical deep dive into what we’ve built and how we have integrated it into our workflow.
Testing agent
The project began with the conviction that LLMs “know” how to use a phone. Anyone can verify this by letting ChatGPT use your phone through you. We also experimented with it in 2023, showing that the model could operate a phone without a human in the loop.
At the heart of our agent is the LLM. We’re using Gemini 2.5 Flash through the Gemini API from a Python application using googleapis/python-genai. Gemini 2.5 flash is capable enough, while being significantly cheaper than the most powerful state-of-the-art models. We do not rule out having to switch to a larger model in the future, but expect the costs to also have come down at that point.
In our Python application we have a bunch of methods that we provide as tools to the LLM. These tools give the LLM access to test cases and allow the LLM observe and control the device that has the app under test.
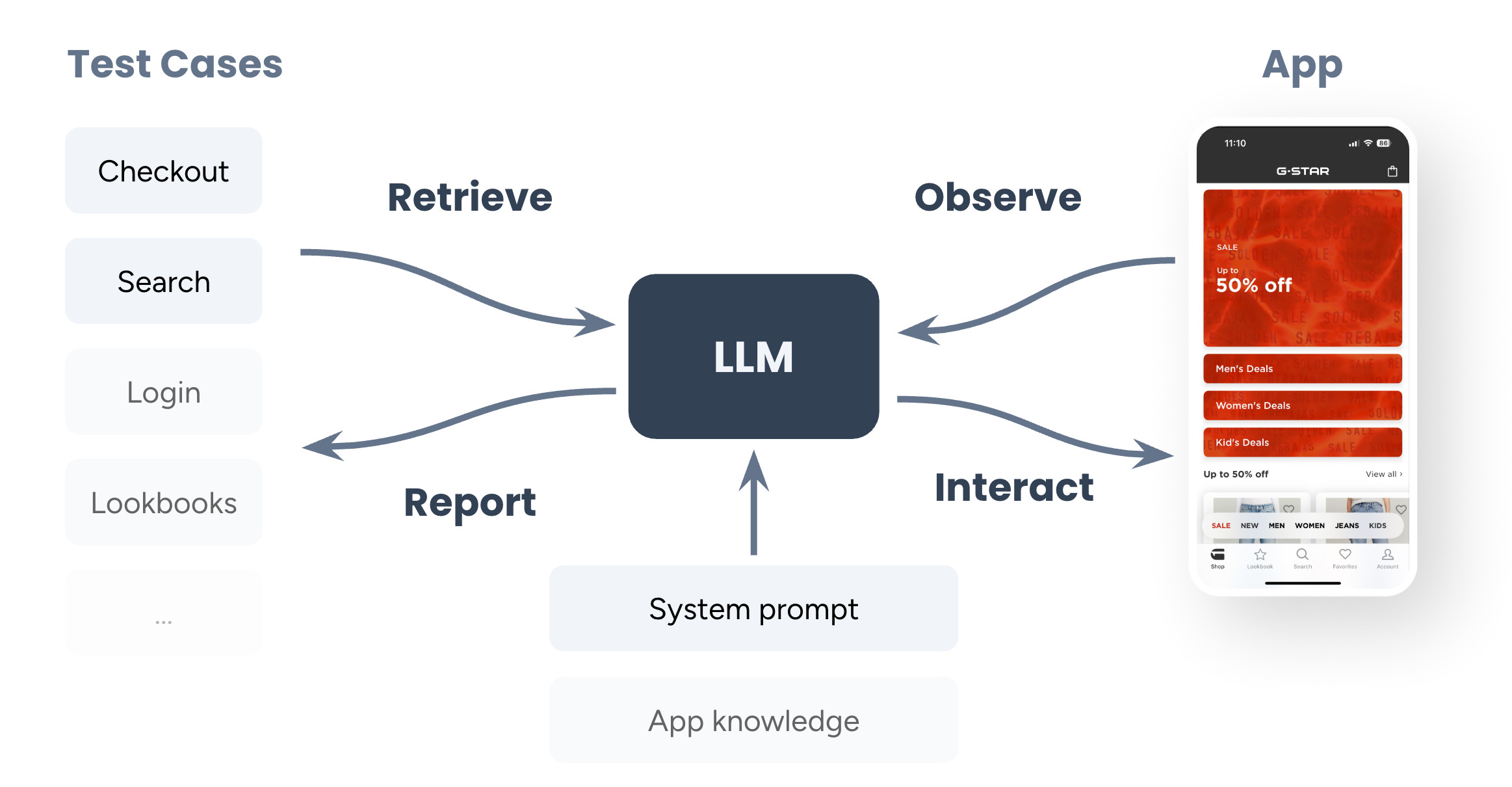
At the start of the test run, the agent calls the get_test_case tool, which returns the first test case. Test cases are written in English and provide the agent with steps to follow and acceptance criteria. Here’s an example:
Test the search functionality of the app: - Launch the app - Go to the search tab and use the category navigation there to navigate to a category - Remember one of the products in that category - Go back to search and search for that product - Verify that the product is found - Verify the search empty state by searching for something that doesn't exist
The agent then uses the launch_app tool to launch the app (optionally with deeplink and/or launch arguments), followed by a call to the ui_describe tool. The latter returns a hierarchical JSON structure that represents everything that can be seen on the screen. This description is powered by the iOS & Android accessibility APIs, the same information used by screen readers and traditional UI test tools, including XCUIAutomation, Espresso and Maestro. Each element in the UI description is assigned a number, which the LLM uses to refer to it in subsequent tool calls.
Based on the UI description and test instructions, the agent will then call a tool to interact with the device. The most common ways of interacting are: tap, type and scroll. On Android it can also tap the system back button, and on both platforms it can use a tool to wait for a certain element to disappear. This allows the agent to wait for loading screens. Every interaction tool returns a status and a new description of the UI.
The agent calls these tools in a loop until it has completed the test case, either because it established the app is behaving correctly, because it found an issue, or because it was blocked from finishing the test case. It reports the result using report_test_result and then calls get_test_case again to get the next test case. When get_test_case returns no new test case, the run is done.
When we start the run, we give the agent a system prompt and provide it with app knowledge. The system prompt is there to make the LLM better at its job. We’re using some well-established prompt techniques to achieve that, including role assignment (“You are a helpful expert UI tester agent”) and few-shot prompting (examples on how to provide rationale for each tool call):
You are a helpful expert UI tester agent. Your goal is to verify if app under test behaves as expected. You'll achieve this goal by interacting with the app according to test cases that the user provides. Use ONLY the provided tools. Do not ask for clarification, make your best attempt to follow the instruction based on the visible UI elements. The element number passed to ui tools MUST correspond to an element in the latest UI description. When you call a tool, you MUST also respond with a rationale for the action. Examples: - "I am on the home screen and I want to go to the account screen, so I will tap the account button." - "I filled in my credentials and I want to submit the form, so I will tap the log in button." - "I am on the wrong screen, so I will tap the back button to go back and try again."
The app knowledge is loaded from a set of agent.md files, which are dynamically added to the context based on the platform and app. These knowledge files, as well as the test cases, live in a separate repository and are cloned before the test run starts.
Integration
The primary output of the run are the test results, conveyed through textual output, status code and a JUnit compatible XML file. In addition to that, our application outputs various artefacts that can be used to validate the test results or debug potential issues: logs of the Python application itself, logs of the app under test, a screen capture, a HAR-archive with all network traffic between the app and our servers and a log of the requests and responses to the LLM.
The UI description and interaction tools are implemented using the UI Testing APIs for each platform. On iOS we’re using a custom built wrapper around UIAutomation. On Android, we’re converting each interaction tool call into a Maestro flow and feed that to a Maestro MCP.
Before the agent can do its thing, and after it is done, there is bookkeeping to be done. Our Python application will create and launch a correctly provisioned iOS Simulator or Android Emulator, it’ll spin up a HTTP proxy, it’ll start recording logs and other artefacts. When the agent is done, all the artefacts are collected and the virtual device is reset to its original state to ensure reliable and reproducible tests.
We run the Python application as part of our CI pipelines. It runs automatically for every release build and can be triggered manually if needed. The job runs on our own M4 Mac Mini runner. The JUnit XML is picked up by GitLab so it’ll show test results in its UI. Additionally, all runs are reported to a dedicated Slack channel.
Conclusion
Our testing agent is graduating from an experiment to something we’re relying on in our day to day work. We are still learning what its capabilities and limitations are. When it reports a failure, it has often gotten stuck instead. In these cases we can inspect the run artefacts to identify potential issues with the UI description (which might require a fix in our Python application) or a gap in the agent’s “understanding” of the app (which can be mitigated by extending the agent.md files). When the agent reports a successful run, we can be relatively certain the app is functioning correctly. In the most important test case, we have the agent navigate the catalog, add products to the cart, proceed to the checkout and fill in its details. Our thinking: if the agent can complete the checkout, so can a user.
Compared to traditional automated UI testing, our testing agent has some interesting advantages and potential drawbacks. Our tests are very easy to write and require little maintenance because they don’t refer to specific UI elements or brand-specific content. This makes it possible to run them in production and across all our apps. Because the tests are so close to the way a real user uses the app, they provide us with a strong safety net. Where the agent may fall short is robustness. Running the tests relies on the Gemini API and the behavior of the LLM. No two test runs are the same, the agent constantly finds a different way to reach its goals. UI Tests are notoriously flaky. Our agent suffers less from the traditional sources of flakiness because of its adaptability, but it does take a “left turn” from time to time. We have ideas to improve that, e.g. by giving the agent more information about our apps upfront and by letting it visually inspect the app during the tests. We also expect these problems to diminish as stronger LLMs become available. We’re confident that the 20-45% of testing time it’s saving us now is just the beginning.
In a future blog post we’ll share how we’re using this agent in a larger multi-agent workflow. We’re expanding the agent’s role beyond the mechanistic execution of test cases and turn it into a “testing buddy” we can pull into conversations about potential issues and have it attempt reproducing them. Make sure to subscribe to our Substack to be notified when that post comes out!
No generative AI was used in the writing of the post.
"No generative AI was used in the writing of the post."
What a delight! :)